
In diesem Artikel handle ich ein kleines Gedankenspiel zum Thema Google Ranking Faktoren ab. Die Kernfrage lautet: wie könnte Google ohne die Daten aus Google Analytics und den Daten aus Google Chrome dennoch die besten Ergebnisse für eine Suchanfrage ermitteln? Und was sind die besten Ergebnisse für eine Suchanfrage in diesem Szenario?
Die besten Ergebnisse für eine Suchanfrage
Um den Google Suchalgorithmus ranken sich bekanntlich viele Mythen. Er ist also so etwas wie die Coca-Cola-Formel für Online-Marketer. Laut offiziellen Aussagen fließen etliche Faktoren in das Ranking der Suchergebnisse mit ein. Abgesehen von diesen offiziell bestätigten Faktoren versuchen findige SEOs weitere Faktoren des Algorithmus zu entziffern und zu ihrem Vorteil zu nutzen.
E-A-T: Neue Richtlinien oder doch ein alter Hut?
Mit der Zeit veröffentlicht Google immer wieder neue suchmaschinenrelevante Richtlinien, die in neuen Buzzwords resultieren und damit neue Trends in der Online-Marketing-Community auslösen. Zuletzt waren das unter anderem die E-A-T-Kriterien.
Auch wenn ich mich dem Thema E-A-T noch nicht vollständig angenommen habe, ist E-A-T (Expertise, Authority & Trust) oder E-E-A-T (Expertise, Experience, Authority & Trust) in aller Munde. Das ist an der Stelle natürlich nicht wörtlich zu verstehen. Also „eat“, „in aller Munde“ … nun ja nicht gerade mein bester Wortwitz. 😅
Laut Google haben die E-A-T-Kritierien keinen direkten Einfluss auf die Suchergebnisse. Das gilt für viele der Faktoren, die für die Bildung des Rankings in den Suchergebnissen verantwortlich sind. Schließlich gibt es nicht den einen entscheiden Rankingfaktor sondern dutzende.
Da ich an dieser Stelle aber auf etwas anderes hinaus möchte, baue ich diesen Artikel auf einer übergeordneten Richtlinie auf.
Für SEOs war bereits vorher bekannt, dass eine Website kein reiner Selbstzweck sein soll, sondern Google vor allem für den Nutzer nützliche Websites belohnt.
Das oberste Ziel der Suchmaschine ist nach wie vor die besten Suchergebnisse für jeden Nutzer darzustellen. Neue Richtlinien zielen also in der Regel auf dieses primäre Ziel ab.
Gehen wir von einer klassischen Nischenseite, SEO-Seite, Affiliate-Seite oder wie auch immer wir das nun nennen wollen aus, dann beschreibt folgender Tweet die Anforderungen an Website-Betreiber ziemlich treffend:
Damit eine Website also dauerhaft erfolgreich ist, sollte diese (logischerweise) nicht aus Spam bestehen, um lediglich auf kurzfristige Gewinne durch Monetarisierung abzielen. Vielmehr sollte die Website von einem richtigen Experten erstellt worden sein, der sich auf seinem Gebiet bestens auskennt und sich obendrein die Mühe macht, diese Informationen so umfangreich wie möglich aufzubereiten.
Anmerkung: das trifft vermutlich (inklusive mir selbst) auf die wenigsten Website-Betreiber zu, die mehr als ein Eisen im Feuer haben wollen. Aber davon lasse ich mich an dieser Stelle nicht entmutigen. Schließlich braucht es Zeit, um Expertise aufzubauen und es spricht aus meiner Sicht nichts dagegen, mit einer inhaltlichen dünnen Website zu starten und diese mit zunehmender Expertise weiter aufzubauen.
Wie könnte Google messen, ob eine Website nützlich ist?
Wir gehen nun im Weiteren davon aus, dass Google möchte, dass unsere Website einen Nutzen für den Besucher hat. Die Rede ist hier wieder ein mal vom häufig zitierten Mehrwert. Dieser Nutzen besteht in der Regel darin, dass die suchende Person ein oder mehrere zur Suchanfrage passende Suchergebnisse erhält. News-Seiten sollen aktuelle Informationen beinhalten, Webshops passende Produkte und Informationswebsites und Ratgeber sollen konkrete Fragen beantworten und so weiter.
Google Ranking Faktoren auswerten: Tracking & Metriken
Damit Google erfährt, ob ein Suchergebnis eine Suchanfrage tatsächlich korrekt bedient hat, müssen Daten erhoben und Metriken ausgewertet werden.
Verlässt der Seitenbesucher unmittelbar oder nach wenigen Sekunden die Website, ist dies in der Regel auf einen technischen Fehler wie zu lange Ladezeiten oder einen fehlerhaften Seitenaufbau zurückzuführen. Funktioniert die Seite hingegen einwandfrei, hat diese offenbar nicht die gesuchten Informationen geliefert beziehungsweise die Suchanfrage erfüllt.
Weitere denkbare Metriken wären die Verweildauer und die Scrolltiefe.
Da Google den Inhalt und damit auch den Umfang einer Seite durch das Crawling kennt, könnte der Algorithmus also ausgehend von einer durchschnittlichen Lesegeschwindigkeit messen, ob ein Seitenbesucher die komplette Seite gelesen hat. Hierfür müsste dieser lediglich den inhaltlichen Umfang einer Seite ins Verhältnis zur Seitenverweildauer setzen.
Im Zusammenspiel mit der Scrolltiefe könnte sich so ein Wert ergeben, der wiedergibt, ob der Inhalt einer Seite vollständig konsumiert wurde oder nicht. Dieser Wert wäre allerdings insofern fehleranfällig, als dass Seitenbesucher häufig nur nach einer bestimmten Information oder Aussage suchen. Diese Information könnte bereits am Anfang des Artikels stehen. Entsprechend wäre die Verweildauer kurz und die Scrolltiefe läge bei wenigen Prozent. Es ergäbe sich also ein schlechter Wert, obwohl die Seite genau die Information geliefert hat, nach der der Seitenbesucher gesucht hat.
Ob diese Metriken in dieser oder einer anderen Form erhoben werden, spielt für den weiteren Gedankengang keine Rolle. Denn um Daten auf einer Website überhaupt erheben zu können, bedarf es eines Trackings. Andernfalls wüsste Google nicht, was genau auf der Website passiert beziehungsweise welche Signale vom Seitenbesucher gesendet werden.
Hat Google Analytics Einfluss auf das Ranking einer Website?
Folgerichtig wurde schon häufig spekuliert, ob die Einbindung von Google Analytics in eine Website einen Vorteil oder Nachteil für den Website-Betreiber bringt.
Google behauptet in einem etwas angestaubten Blogbeitrag aus dem Jahr 2010, dass dem nicht so ist. Allerdings drängt sich mir die Frage auf, warum Google diese Daten nicht nutzen sollte.
Ich schätze Google und insbesondere den Suchalgorithmus so ein, dass dieser die Abwesenheit von Google Analytics zwar nicht bestraft, aber die Daten aus Google Analytics durchaus nutzt, um Löcher in den Daten zu stopfen, die ansonsten geschätzt oder interpoliert werden müssten.
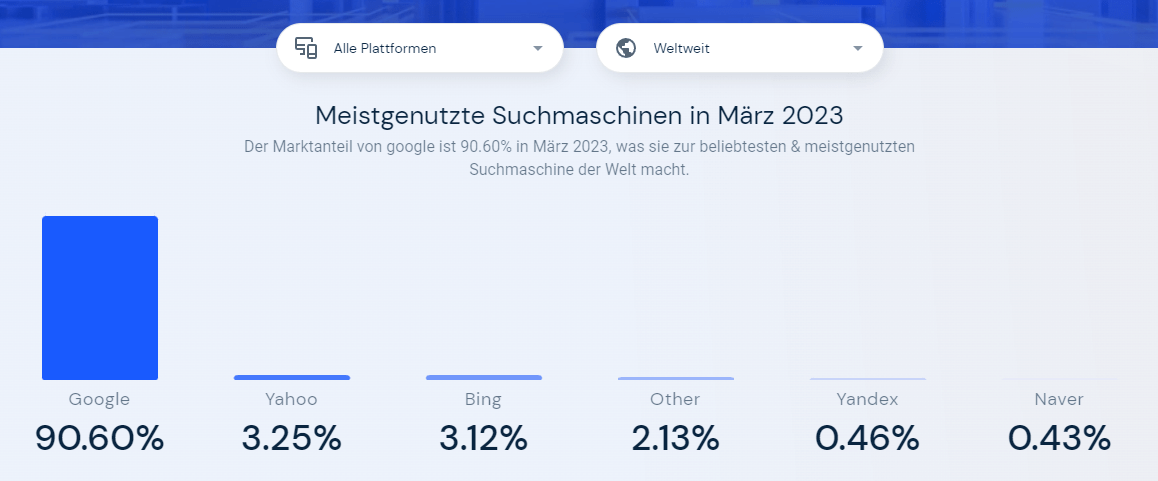
Leider konnte ich keine zuverlässige Statistik dazu finden, auf wie vielen Websites Google Analytics eingebunden ist, geschweige denn wie hoch der Marktanteil von Google Analytics ist.
Wikipedia spricht hier von 50 bis 80 %, nennt allerdings selbst keine Quelle für diese Angabe. Dennoch halte ich dies für einen realistischen Wert.
Entscheidend ist hier aber vor allem, dass Google Analytics nicht auf einen Marktanteil oder in die Nähe eines Marktanteils von 100% kommt.
Dieser Umstand spricht aus meiner Sicht nämlich gegen Google Analytics als primäre Datenquelle für die Erhebung von Nutzersignale für den Suchalgorithmus.
Zwar würde man mit einem geschätztem Marktanteil zwischen 50 und 80 % bereits ein repräsentatives Ergebnis erhalten, allerdings könnte man auf Basis dieser lückenhaften Google Analytics Daten keine spezifischen Websites auf ihre Nützlichkeit hin beurteilen.
Datenerhebung der Nutzererfahrung mittels Google Chrome
Wenn Google nicht direkt an die Daten auf einer Website kommt, ginge dies natürlich indirekt auf einer anderen Abstraktionsebene über den hauseigenen Browser Chrome.
Ob und in welchem Umfang Google Chrome Nutzerdaten in Form von Signalen auf Websites auswertet, konnte mir selbst der Blick in den Google Blog nicht verraten.
Aber auch hier liegt die Vermutung nahe, dass es seitens Google fahrlässig wäre, wenn nicht zumindest die Nutzerdaten für die Suchergebnisse ausgewertet würden, die man datenschutztechnisch korrekt, also beispielsweise anonymisiert, erfassen kann.
Daher halte ich es für wahrscheinlich, dass die beiden vorher genannten Services dabei helfen die wesentlich kleinere Lücke in der Datenlage der Suchmaschine zu schließen.
Doch wie könnte Google nur über Auswertung der eigenen Suchmaschine und ohne externes Tracking via Browser oder Google Analytics ermitteln, ob eine Suchanfrage bedient wurde oder nicht?
Google Ranking Faktoren ermitteln ohne auf externe Daten zurückzugreifen
Kommen wir nun zur Kernüberlegung dieses Gedankenspiels: wie könnte Google nur über die Suchmaschine erkennen, ob eine Seite mit ihrem Inhalt eine Suchintention bedient oder nicht.
Definition
Hierfür definiere ich einmal kurz, was an dieser Stelle überhaupt als nützlich zu verstehen ist.
Ein Suchergebnis ist dann nützlich, wenn die Suchanfrage vollständig bedient wurde beziehungsweise wenn keine weiteren Suchen zum ursprünglichen Keyword durch den Nutzer durchgeführt werden.
Einige Annahmen
Damit meine Theorie etwas mehr Sinn ergibt, müssen noch einige Annahmen getroffen werden.
- Der Nutzer wechselt für jede einzelne Suchanfrage zum einem Thema nicht das komplettes Setup. Er bleibt also in der selben Session innerhalb des selben Browsers ohne seine Internetverbindung und damit seine IP-Adresse zu ändern.
- Der Nutzer ruft Google über einen neutralen Browser auf, der in keinerlei Verbindung zu Google steht und damit also potenziell keine Nutzungsdaten oder sonstigen Signale übermitteln kann.
- Der Nutzer ist zu keiner Zeit in sein Google Konto eingeloggt.
- Es gibt auf der Seite der Suchmaschine ein Tracking. Im Folgenden Session-Tracking genannt.
Damit ist. abgesehen vom Tracking der Suchmaschine selbst, jegliche Datenerhebung ausgeschlossen.
Reichen diese Daten dennoch, um das Nutzerverhalten auf fremden Seiten, von denen Google keine Daten erhält, zu messen? Aus meiner Sicht, ganz klar ja!
Ich versuche dies nun an einem Beispiel zu erläutern.
Beispiel
Nehmen wir an, ich suche ich nach einer Methode, um meine Fenster streifenfrei zu putzen.
Ich tippe meine Suchanfrage über einen neutralen Browser in Google ein.
Session Start
Damit hat eine Session begonnen und Google kennt meine IP-Adresse. Selbst wenn ich initial alle Cookies ablehne und meine Session nicht mit meinen sonstigen Aktivitäten in Verbindung gesetzt werden kann, sind alle Interaktionen innerhalb der Session eindeutig meiner IP zuordenbar beziehungsweise meinem temporären Profil zuordnen bar.
Abgesehen davon weiß Google für die Dauer dieser Session, dass ich schmutzige Fenster habe. Diese Information erlischt mit der Beendigung der Session bzw. kann nicht mit meinem eigentlichen Profil in Verbindung gesetzt werden. Das Problem meiner verschmierten Fenster bleibt leider weiter bestehen. Aber zurück zum Thema. :-D
Ich sehe nun die Suchergebnisse zum Keyword Fenster streifenfrei putzen.
Die Positionen 1 bis 3 teilen sich Amazon, idealo und Kärcher, die all ihre SEO-Power gesammelt haben, um jeweils eine Seite auf dieses Keyword zu optimieren. Ich bin noch nicht bereit mein Problem direkt durch den Kauf eines Produktes zu lösen und entscheide mich daher weiter zu scrollen.
Interaktion mit SERPs
Auf Position 4 hat sich ein gewiefter Webseitenbetreiber hochgearbeitet. Seine Website endlich-saubere-fenster.de scheint genau das zu sein, wonach ich gesucht habe.
Ich rufe die Seite auf und sende damit ein Signal an das Session-Tracking. Spätestens jetzt weiß das Session-Tracking, dass ich die Suchergebnisse 1 bis 3 als unpassend für meine Suchanfrage empfunden habe.
Seitenbesuch
Ich befinde mich nun auf endlich-saubere-fenster.de und überfliege den 5.000 Wörter Text zum Thema Fenster streifenfrei putzen.
Leider stelle ich fest, dass man sich hier zwar viel Mühe mit einem möglichst umfangreichen Text gegeben hat, allerdings kann ich nach knapp einer Minute keine Lösung für mein Problem finden. Ich verlasse die Seite.
Das Session-Tracking erwartet mich noch nicht zurück. Schließlich weiß Google, dass ich mir gerade eigentlich einen 5.000 Wörter langen Text durchlesen müsste, was bei einer geschätzten Lesegeschwindigkeit von 250 Wörtern pro Minute exakt 20 Minuten dauern würde.
Interaktion mit SERPs
Zurück auf Google springt mir das Suchergebnis auf Position 5 der Gebäudereinigung Meier ins Auge.
Seitenbesuch
Ich rufe die Seite der Gebäudereinigung Meier auf. Auf der Seite ist ein Video eingebunden, dass zwar etwas laienhaft gedreht wurde. In diesem Video demonstriert Herr Meier persönlich, wie man ein Fenster streifenfrei reinigt.
Session Ende
All meine Frage sind beantwortet. Ich schließe den Tab und ggf. den kompletten Browser. Woher weiß Google nun, dass mir die Gebäudereinigung Meier helfen konnte?
Ganz einfach: in meiner Session findet keine weitere Suchanfrage statt. Ebenfalls interagiere ich innerhalb meiner Session mit keinem weiteren Suchergebnis.
Ich die Session beendet. Offensichtlich habe ich gefunden, wonach ich gesucht habe und die Gebäudereinigung Meier bekommt entsprechende positive Signale für das Keyword Fenster streifenfrei putzen gutschrieben.
Fazit
Auch wenn ich an dieser Stelle noch einmal betonen möchte, dass es sich hierbei lediglich um ein Gedankenspiel handelt und ein großer Teil meiner Theorie auf Mutmaßung basiert, halte ich es für sehr wahrscheinlich, dass Google jede sinnvolle interne Datenquelle nutzt, um die eigenen Suchergebnisse zu verbessern.
Selbstverständlich ist dieses Gedankenspiel eine starke Vereinfachung und bezieht sich nur auf einen von vielen Faktoren, die am Ende in die Darstellung der Suchergebnisse fließen.
Du bist anderer Meinung? Sehr gut! Lass uns gerne diskutieren! Schreibe mich dazu gerne direkt über LinkedIn, Twitter oder wo auch immer an oder noch besser: teile diesen Artikel, erkläre ihn für völligen Unsinn und markiere mich. Dann können wir gerne über Details diskutieren. :-)
Quellen und weiterführende Links
- https://developers.google.com/search/blog/2022/12/google-raters-guidelines-e-e-a-t
- https://www.google.com/intl/de/search/howsearchworks/how-search-works/ranking-results/
- https://developers.google.com/search/blog/2010/03/beeinflusst-google-analytics-das
- https://blog.google/
- https://de.statista.com/statistik/daten/studie/158095/umfrage/meistgenutzte-browser-im-internet-weltweit/
- https://www.similarweb.com/de/engines/
- https://policies.google.com/privacy
